 In recent years, it has gotten much simpler to develop light-weight applications, that can visually detect and identify objects with entry-level hardware, like using a webcam as the main camera. This article explains a simple, yet flexible approach on how to realize such a solution.
In recent years, it has gotten much simpler to develop light-weight applications, that can visually detect and identify objects with entry-level hardware, like using a webcam as the main camera. This article explains a simple, yet flexible approach on how to realize such a solution.AI Showcase - Object Detection Using the Example of Fruits

Sophia Giraldo – Working Student (Data Science)
In recent years, it has gotten much simpler to develop light-weight applications, that can visually detect and identify objects with entry-level hardware, like using a webcam as the main camera. This article explains a simple, yet flexible approach on how to realize such a solution.There are lots of use cases for object detection and identification. For example, if a product development department wants to improve a product based on known issues of previous generations, like frequently occurring damages, it is vital to have good overview and knowledge about those occurring damages. However, it is time-consuming and prone to errors to take photos of each product that is returned by customers, assigning the corresponding defect and storing this information correctly without any human-error. Therefore, a sensible approach is to automatically detect the visible deviation (the defect) and store all other known relevant metadata (e. g. age of product, industry the product was used, date of inspection). In this way, the process is significantly simplified and becomes more efficient, reducing errors in data collection. Consequently, this makes it easier to identify and improve any potential in the weak points of their products.
In general, the reason for image detection projects are often the topics of our time: Maintenance, efficiency, evidence, digitalisation.
Our approach encounters image classification, segmentation, and annotation. By using various machine learning methods and techniques, we offer a cost-effective (in terms of computing and development time) solution. By means, a robust and efficient solution that can be used locally and without extra charge per time used. Furthermore, this solution can easily be adjusted by reinforcing knowledge of the algorithm within a very short period of time, and again, very efficiently. In the end, it is a powerful tool for automated image analysis.
In the present article, we use a non-industry use case as an example. Why? As we all know, data privacy concerns and the protection of intellectual property are a big matter. Hence, images and all other data from the industrial contexts can not be shared/published. What are we using then? Fruits! We detect where the fruit is and which fruit it is – however, the use case can be switched easily as you will find out.
Use Case: Fruit Detection
 The fruit detector demonstrates end-to-end photo-based detection and classification. The dashboard displays the results and allows the recognized fruit varieties to be confirmed or changed. At its core, the solution consists of a pre-trained neural network. This can be further trained for the respective use case, in this case the detection of fruits.
The fruit detector demonstrates end-to-end photo-based detection and classification. The dashboard displays the results and allows the recognized fruit varieties to be confirmed or changed. At its core, the solution consists of a pre-trained neural network. This can be further trained for the respective use case, in this case the detection of fruits.
The data set for the training for this demonstrator was created by us and consists of 360 images of different fruit combinations. A standard computer with a normal webcam is all that is needed to run it, and no internet connection is required for detection.
The Demonstrator: Steps and components
- Dataset preparation:
- Selected classes: apple 🍎, banana 🍌, grape 🍇, lemon 🍋, mango 🥭, pear 🍐, strawberry 🍓 and orange 🍊
- Building dataset: individual (1 class) photo for different (3 to 4) angles, 2 or more classes per picture varying angles (non-overlapping and overlapping)
- Annotation (inside AI Custom Vision)
- Training: Azure AI Custom Vision is a service by which we build, deploy and improve our own image identifier model, in our case: object detection. It uses a machine learning algorithm to analyse images. The algorithm trains with the dataset we provide and it calculates 3 statistics: precision, recall and mAP.
- Precision: How likely is it that the model will make the correct class prediction.
- Recall: from our corresponding labelling, which percentage did the model found.
- mAP (mean average precision): overall object detection performance across all our labels.
- Prerequisites:
- Set of images for training the detection model (more than 50 images per class). Take into account visual varieties, such as: angle, lightning, background, individual/grouped, size, others.
- Have the Custom Vision Training and Prediction resources.
- Dashboard:
The dashboard of our system provides a comprehensive overview of various functions and modules available to users. The following paragraph guides you through the different views.
With the menupoint Obsterkenner, users can take a picture, which is then visualized with detected objects and their corresponding predicted classes. Scores are displayed, allowing users to annotate the number of true objects present and save the data. Under the section Hintergrund a brief description of the technical details involved in implementing the demonstrator is offered.
 Under Tainingsfotos sample training photos are displayed to give users an idea of the training dataset an Verlauf shows the last ten pictures taken. The menupoint Statistik compares model predictions with actual values and Histogram displays the frequency of predictions versus real values for each type of fruit. The Pie chart visualizes the misclassification loss for each fruit, with larger areas indicating worse classification. Finally, the section Kontakt briefly describes what our Data Science team can do and encourages users to reach out to us for potential future projects.
Under Tainingsfotos sample training photos are displayed to give users an idea of the training dataset an Verlauf shows the last ten pictures taken. The menupoint Statistik compares model predictions with actual values and Histogram displays the frequency of predictions versus real values for each type of fruit. The Pie chart visualizes the misclassification loss for each fruit, with larger areas indicating worse classification. Finally, the section Kontakt briefly describes what our Data Science team can do and encourages users to reach out to us for potential future projects. - Storage: SQLite → storage predicted counts and real counts for each class. (Purpose: visualisation of statistics)
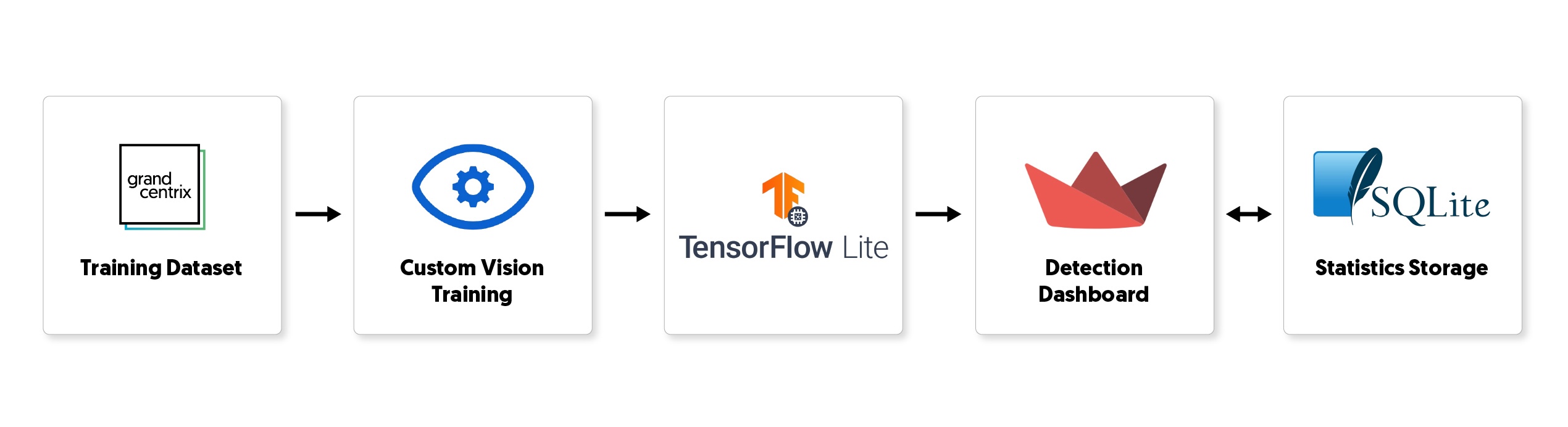
- Architecture: The dataset is passed to Custom Vision and it is labeled before realizing the training. After the training the model is exported as a TensorFlow model. The user interface, where the fruits are detected, is implemented in Streamlit. At last, for future analysis the predictions statistics are stored in SQLite database.
Summary of the Benefits
In summary we established that a solution like this is useful because it:
- Improves Efficiency: Automates object detection and identification, saving time and reducing errors.
- Enhances Accuracy: Provides reliable identification and classification.
- Reduces Costs: Operates locally without ongoing costs.
- Adaptable and Scalable: Easily retrained for various applications.
- Facilitates Data Collection: Automatically captures and stores relevant metadata for analysis and improvement.
Fun Facts:
- 95% of the time, humans head are detected as mangos 🥭.
- Building a dataset can get very creative if you think about all the combinations of angles, perspectives, lights and backgrounds within the image/object.
- Our Demonstrator is exhibited at the Forum Digital Technologies in Berlin so you can actually try it yourself.
Background: Why was this initiated?
As part of the Service Meister project, an AI research project funded by the BMWK, grandcentrix and Würth implemented an image-based defect detection system for power tools that are visibly damaged as a result of falls, for example. The idea is that a user interacts with a browser-based application. To demonstrate how easily such a solution can be generalized and used for a completely different application, we provide the solution for the recognition of different types of fruit. The main motivation of this demonstrator is to show that the challenge of adequately applying image identification has become much smaller in recent years. Existing, pre-trained models can be used and further trained for the respective application. For certain applications, as few as 50 training images per new object class to be identified may be sufficient. Of course, the number of training images required for sufficient performance depends on many things, such as the uniformity of the image background, the noise level of the image, the similarity of the different objects of interest and the accuracy requirements of the model in the use case under discussion.